Important concepts
How much of your build gets loaded from the cache depends on many factors. In this section you will see some of the tools that are essential for well-cached builds. Build scans are part of that toolchain and will be used throughout this guide.
Build cache key
Artifacts in the build cache are uniquely identified by a build cache key. A build cache key is assigned to each cacheable task when running with the build cache enabled and is used for both loading and storing task outputs to the build cache. The following inputs contribute to the build cache key for a task:
-
The task implementation
-
The task action implementations
-
The names of the output properties
-
The names and values of task inputs
Two tasks can reuse their outputs by using the build cache if their associated build cache keys are the same.
Repeatable task outputs
Assume that you have a code generator task as part of your build. When you have a fully up to date build and you clean and re-run the code generator task on the same code base it should generate exactly the same output, so anything that depends on that output will stay up-to-date.
It might also be that your code generator adds some extra information to its output that doesn’t depend on its declared inputs, like a timestamp. In such a case re-executing the task will result in different code being generated (because the timestamp will be updated). Tasks that depend on the code generator’s output will need to be re-executed.
When a task is cacheable, then the very nature of task output caching makes sure that the task will have the same outputs for a given set of inputs. Therefore, cacheable tasks should have repeatable task outputs. If they don’t, then the result of executing the task and loading the task from the cache may be different, which can lead to hard-to-diagnose cache misses.
In some cases even well-trusted tools can produce non-repeatable outputs, and lead to cascading effects.
One example is Oracle’s Java compiler, which, due to a bug, was producing different bytecode depending on the order source files to be compiled were presented to it.
If you were using Oracle JDK 8u31 or earlier to compile code in the buildSrc subproject, this could lead to all of your custom tasks producing occasional cache misses, because of the difference in their classpaths (which include buildSrc).
The key here is that cacheable tasks should not use non-repeatable task outputs as an input.
Stable task inputs
Having a task repeatably produce the same output is not enough if its inputs keep changing all the time. Such unstable inputs can be supplied directly to the task. Consider a version number that includes a timestamp being added to the jar file’s manifest:
version = "3.2-${System.currentTimeMillis()}"
tasks.jar {
manifest {
attributes(mapOf("Implementation-Version" to project.version))
}
}version = "3.2-${System.currentTimeMillis()}"
tasks.named('jar') {
manifest {
attributes('Implementation-Version': project.version)
}
}In the above example the inputs for the jar task will be different for each build execution since this timestamp will continually change.
Another example for unstable inputs is the commit ID from version control.
Maybe your version number is generated via git describe (and you include it in the jar manifest as shown above).
Or maybe you include the commit hash directly in version.properties or a jar manifest attribute.
Either way, the outputs produced by any tasks depending on such data will only be re-usable by builds running against the exact same commit.
Another common, but less obvious source of unstable inputs is when a task consumes the output of another task which produces non-repeatable results, such as the example before of a code generator that embeds timestamps in its output.
A task can only be loaded from the cache if it has stable task inputs. Unstable task inputs result in the task having a unique set of inputs for every build, which will always result in a cache miss.
Better reuse via input normalization
Having stable inputs is crucial for cacheable tasks. However, achieving byte for byte identical inputs for each task can be challenging. In some cases sanitizing the output of a task to remove unnecessary information can be a good approach, but this also means that a task’s output can only be normalized for a single purpose.
This is where input normalization comes into play. Input normalization is used by Gradle to determine if two task inputs are essentially the same. Gradle uses normalized inputs when doing up-to-date checks and when determining if a cached result can be re-used instead of executing the task. As input normalization is declared by the task consuming the data as input, different tasks can define different ways to normalize the same data.
When it comes to file inputs, Gradle can normalize the path of the files as well as their contents.
Path sensitivity and relocatability
When sharing cached results between computers, it’s rare that everyone runs the build from the exact same location on their computers. To allow cached results to be shared even when builds are executed from different root directories, Gradle needs to understand which inputs can be relocated and which cannot.
Tasks having files as inputs can declare the parts of a file’s path what are essential to them: this is called the path sensitivity of the input.
Task properties declared with ABSOLUTE path sensitivity are considered non-relocatable.
This is the default for properties not declaring path sensitivity, too.
For example, the class files produced by the Java compiler are dependent on the file names of the Java source files: renaming the source files with public classes in them would fail the build.
Though moving the files around wouldn’t have an effect on the result of the compilation, for incremental compilation the JavaCompile task relies on the relative path to find other classes in the same package.
Therefore, the path sensitivity for the sources of the JavaCompile task is RELATIVE.
Because of this only the normalized (relative) paths of the Java source files are considered as inputs to the JavaCompile task.
The Java compiler only respects the package declaration in the Java source files, not the relative path of the sources.
As a consequence, path sensitivity for Java sources is NAME_ONLY and not RELATIVE.
|
Content normalization
Compile avoidance for Java
When it comes to the dependencies of a JavaCompile task (i.e. its compile classpath), only changes to the Application Binary Interface (ABI) of these dependencies require compilation to be executed.
Gradle has a deep understanding of what a compile classpath is and uses a sophisticated normalization strategy for it.
Task outputs can be re-used as long as the ABI of the classes on the compile classpath stays the same.
This enables Gradle to avoid Java compilation by using incremental builds, or load results from the cache that were produced by different (but ABI-compatible) versions of dependencies.
For more information on compile avoidance see the corresponding section.
Runtime classpath normalization
Similar to compile avoidance, Gradle also understands the concept of a runtime classpath, and uses tailored input normalization to avoid running e.g. tests. For runtime classpaths Gradle inspects the contents of jar files and ignores the timestamps and order of the entries in the jar file. This means that a rebuilt jar file would be considered the same runtime classpath input. For details on what level of understanding Gradle has for detecting changes to classpaths and what is considered as a classpath see this section.
Filtering runtime classpaths
For a runtime classpath it is possible to provide better insights to Gradle which files are essential to the input by configuring input normalization.
Given that you want to add a file build-info.properties to all your produced jar files which contains volatile information about the build, e.g. the timestamp when the build started or some ID to identify the CI job that published the artifact.
This file is only used for auditing purposes, and has no effect on the outcome of running tests.
Nonetheless, this file is part of the runtime classpath for the test task. Since the file changes on every build invocation, tests cannot be cached effectively.
To fix this you can ignore build-info.properties on any runtime classpath by adding the following configuration to the build script in the consuming project:
normalization {
runtimeClasspath {
ignore("build-info.properties")
}
}normalization {
runtimeClasspath {
ignore 'build-info.properties'
}
}If adding such a file to your jar files is something you do for all of the projects in your build, and you want to filter this file for all consumers, you may wrap the configurations described above in an allprojects {} or subprojects {} block in the root build script.
The effect of this configuration would be that changes to build-info.properties would be ignored for both up-to-date checks and task output caching.
All runtime classpath inputs for all tasks in the project where this configuration has been made will be affected.
This will not change the runtime behavior of the test task — i.e. any test is still able to load build-info.properties, and the runtime classpath stays the same as before.
The case against overlapping outputs
When two tasks write to the same output directory or output file, it is difficult for Gradle to determine which output belongs to which task. There are many edge cases, and executing the tasks in parallel cannot be done safely. For the same reason, Gradle cannot remove stale output files for these tasks. Tasks that have discrete, non-overlapping outputs can always be handled in a safe fashion by Gradle. For the aforementioned reasons, task output caching is automatically disabled for tasks whose output directories overlap with another task.
Build scans show tasks where caching was disabled due to overlapping outputs in the timeline:
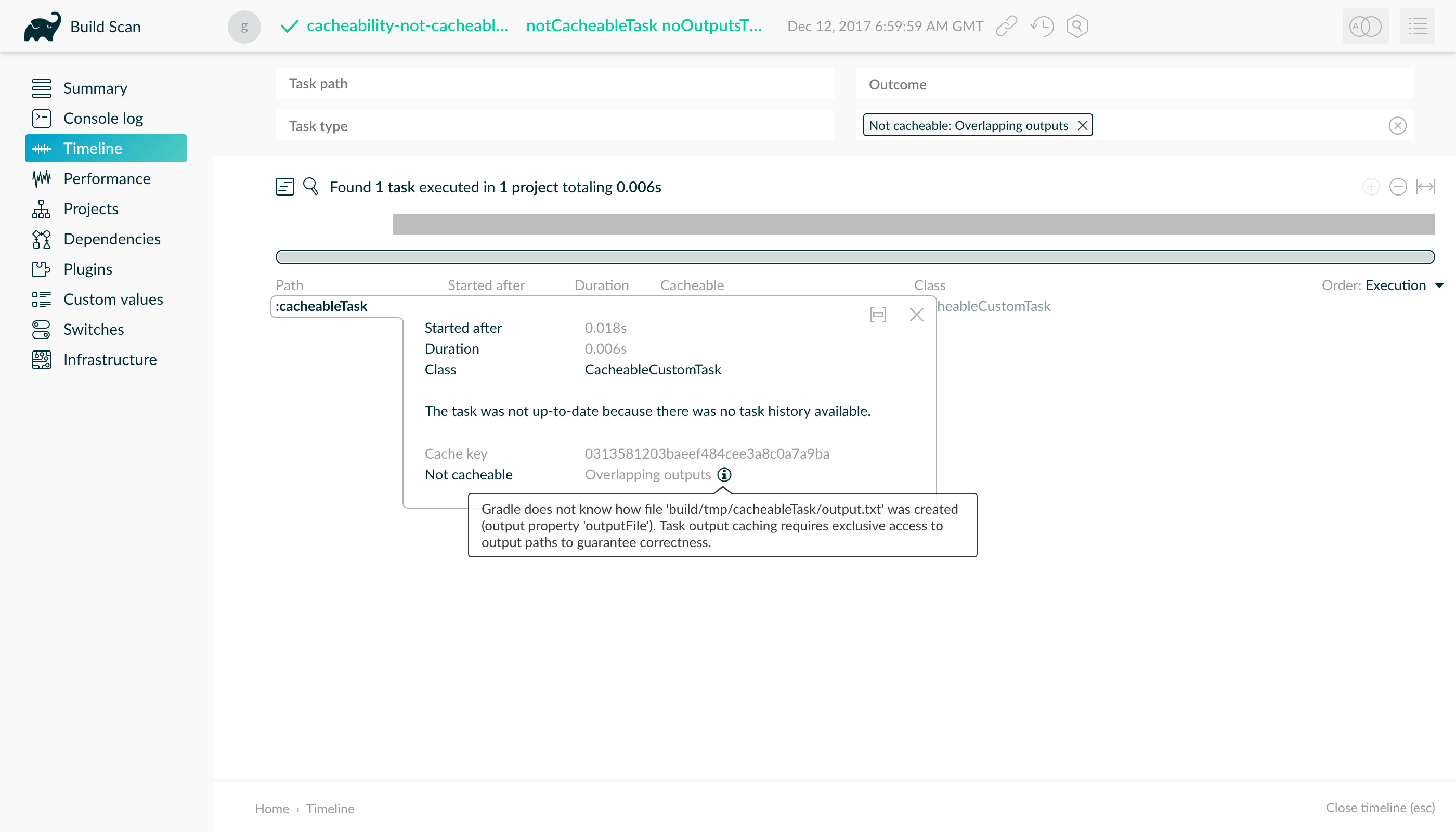
Reuse of outputs between different tasks
Some builds exhibit a surprising characteristic: even when executed against an empty cache, they produce tasks loaded from cache. How is this possible? Rest assured that this is completely normal.
When considering task outputs, Gradle only cares about the inputs to the task: the task type itself, input files and parameters etc., but it doesn’t care about the task’s name or which project it can be found in.
Running javac will produce the same output regardless of the name of the JavaCompile task that invoked it.
If your build includes two tasks that share every input, the one executing later will be able to reuse the output produced by the first.
Having two tasks in the same build that do the same might sound like a problem to fix, but it is not necessarily something bad. For example, the Android plugin creates several tasks for each variant of the project; some of those tasks will potentially do the same thing. These tasks can safely reuse each other’s outputs.
As discussed previously, you can use Develocity to diagnose the source build of these unexpected cache-hits.
Non-cacheable tasks
You’ve seen quite a bit about cacheable tasks, which implies there are non-cacheable ones, too. If caching task outputs is as awesome as it sounds, why not cache every task?
There are tasks that are definitely worth caching: tasks that do complex, repeatable processing and produce moderate amounts of output. Compilation tasks are usually ideal candidates for caching.
At the other end of the spectrum lie I/O-heavy tasks, like Copy and Sync. Moving files around locally typically cannot be sped up by copying them from a cache.
Caching those tasks would even waste good resources by storing all those redundant results in the cache.
Most tasks are either obviously worth caching, or obviously not. For those in-between a good rule of thumb is to see if downloading results would be significantly faster than producing them locally.